Metadaten mit Harvester hochladen
Wie lade ich meine Metadaten mittels Harvester hoch?
Mit einem Harvester lassen sich grössere Datenmengen einfach und schnell publizieren. Es bedeutet, dass Ihre Datasets automatisch durch opendata.swiss aktualisiert werden können, der Aufwand für die Datenpflege reduziert sich für Sie. Voraussetzung dafür ist, dass Ihre Organisation mitsamt Benutzerinnen und Benutzern registriert ist. Dies erfolgt in Absprache mit der Geschäftsstelle OGD. Wir erklären Ihnen hier, wie das Harvesting funktioniert.
Die Schritte auf einen Blick
Gut zu wissen
Sollten Sie zum ersten Mal Daten publizieren, führen wir Sie durch den Prozess und unterstützen Sie dabei, die korrekte Übermittlung und Darstellung Ihrer Daten sicherzustellen, unabhängig von der Publikationsvariante.
Alle Schritte im Detail
Harvester einrichten
Wenn Sie Ihre Daten im Standard DCAT-AP-CH bereitstellen können, übernehmen wir das Einrichten des Harvesters für Sie. Sie müssen nichts weiter tun, als uns die URL mit dem Katalog-Endpunkt zu übermitteln. In speziellen Fällen, zum Beispiel wenn ein Datenkatalog nicht im DCAT-AP-CH Standard geliefert werden kann, kann ein spezifisches Mapping definiert werden. Bitte kontaktieren Sie uns hierfür.
Gut zu wissen
Pro Organisation wird jeweils ein Endpunkt für das Harvesten benötigt. Falls Sie also Daten von mehreren Organisationen verwalten, benötigen wir auch mehrere Endpunkte. Beachten Sie beim Vorbereiten Ihres Datenkatalogs die besondere Struktur des Dataset-Identifiers, die im Standard DCAT-AP-CH beschrieben ist und für jede Organisation individuell ist.
Katalog-Endpunkt übergeben
Senden Sie uns hierfür eine E-Mail mit der URL, unter der wir Ihren Datenkatalog herunterladen können. Diese URL ist gleichzeitig ein RDF-Endpunkt.
Wichtig: Der Datenkatalog muss im Format DCAT-AP-CH vorliegen.
Katalog-Endpunkt mit Paginierung übergeben
<hydra:PagedCollection rdf:about="http://opendata.swiss/catalog.xml?page=3">
<hydra:lastPage>http://opendata.swiss/catalog.xml?page=4</hydra:lastPage>
<hydra:itemsPerPage rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">1000</hydra:itemsPerPage>
<hydra:totalItems rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">3479</hydra:totalItems>
<hydra:firstPage>http://opendata.swiss/catalog.xml?page=1</hydra:firstPage>
<hydra:previousPage>http://opendata.swiss/catalog.xml?page=2</hydra:previousPage>
</hydra:PagedCollection>
Falls Ihr Datenkatalog zu gross ist und nicht in einer einzigen Anfrage übermittelt werden kann, besteht die Möglichkeit, ihn seitenweise zu übergeben. Dafür empfehlen wir, die Paginierung mit dem Hydra Vocabulary zu implementieren. Senden Sie uns anschliessend eine E-Mail mit der entsprechenden URL.
Harvester testen
Das Harvesting von Datasets im DCAT-AP-CH Standard wird von uns für Sie getestet. Nachdem wir Ihre URL erhalten und den Harvester eingerichtet haben, lassen wir ihn auf Ihrem Endpunkt in der Abnahmeumgebung erstmalig laufen. Unter Umständen liefert der Harvester anfangs Fehler zurück, die Sie dann in Ihrem Datenkatalog beheben müssen.
Am Prozess des Testens und der iterativen Verbesserung Ihrer Daten sind Sie von Anfang an mit einbezogen. Sie haben selbst Zugang zu Ihrem Harvester, seinen Jobläufen und Fehlerberichten. Sollten Sie bei allfälligen Fehlern Fragen haben, dann wenden Sie sich bitte an uns und wir helfen Ihnen weiter
Den Harvester verwalten
Im Folgenden erklären wir Ihnen den Zugang zu Ihrem Harvester:
Klicken Sie auf den Button «Harvest Sources». Dann gelangen Sie zu einer Liste aller Harvester. Geben Sie den Namen Ihres Harvesters ins Suchfeld ein, um nach Ihrem Harvester zu finden. Den Namen des Harvesters erhalten Sie von uns.
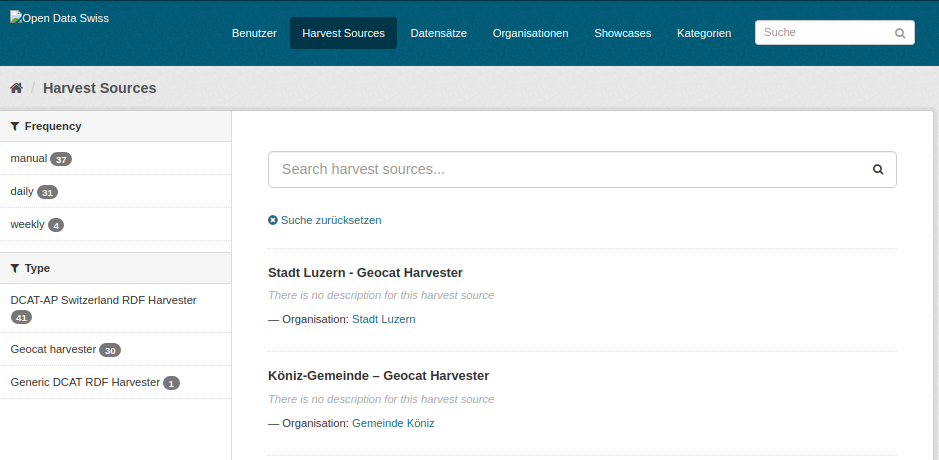
Wenn Sie Ihren Harvester gefunden haben: klicken Sie auf den Link, dann gelangen Sie zur Detailansicht des Harvesters:

In der Detailansicht Ihres Harvesters sind alle Datasets aufgelistet, die der Harvester über den Zugriff auf Ihren Katalog Endpunkt automatisch erzeugt hat.
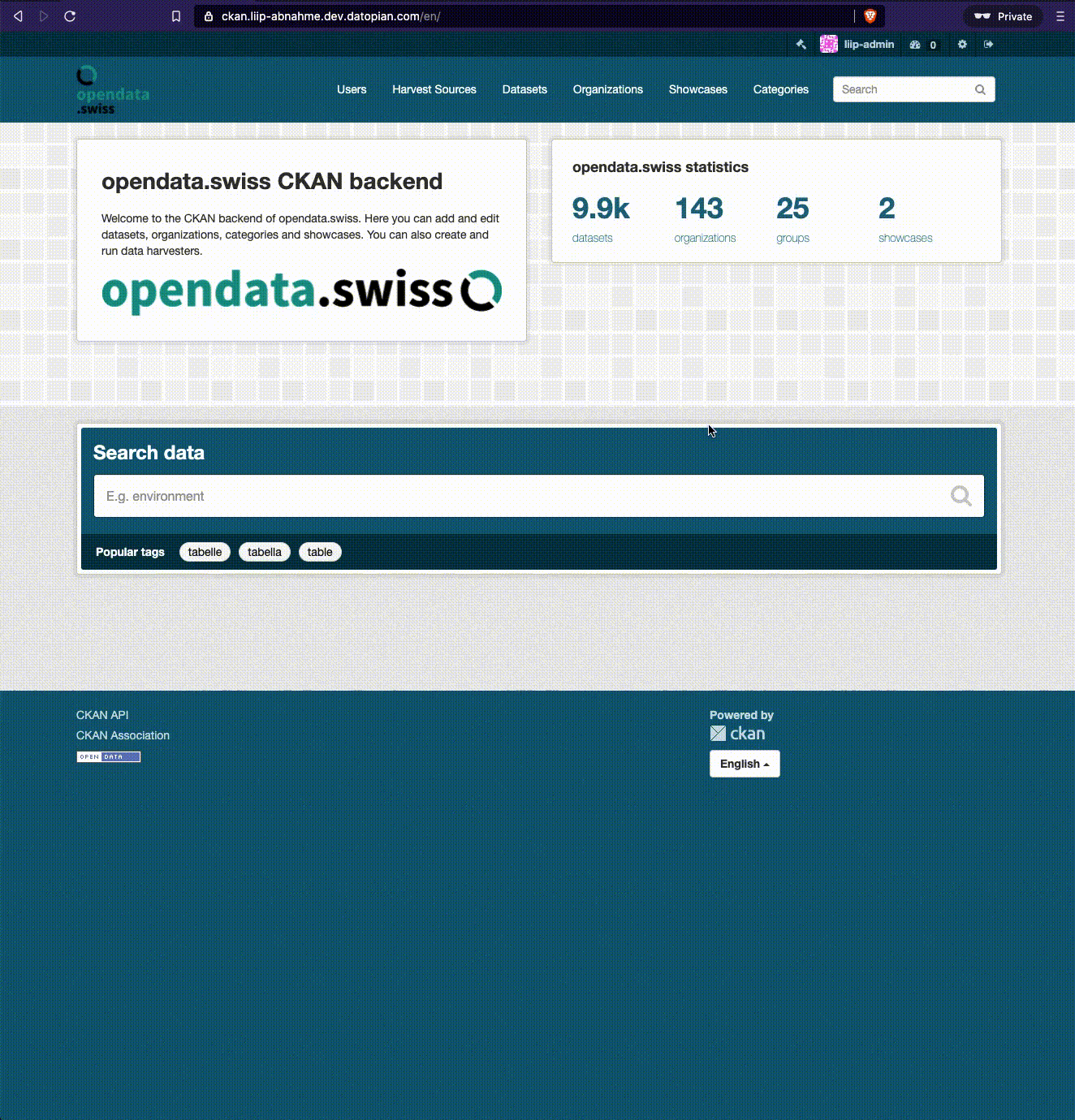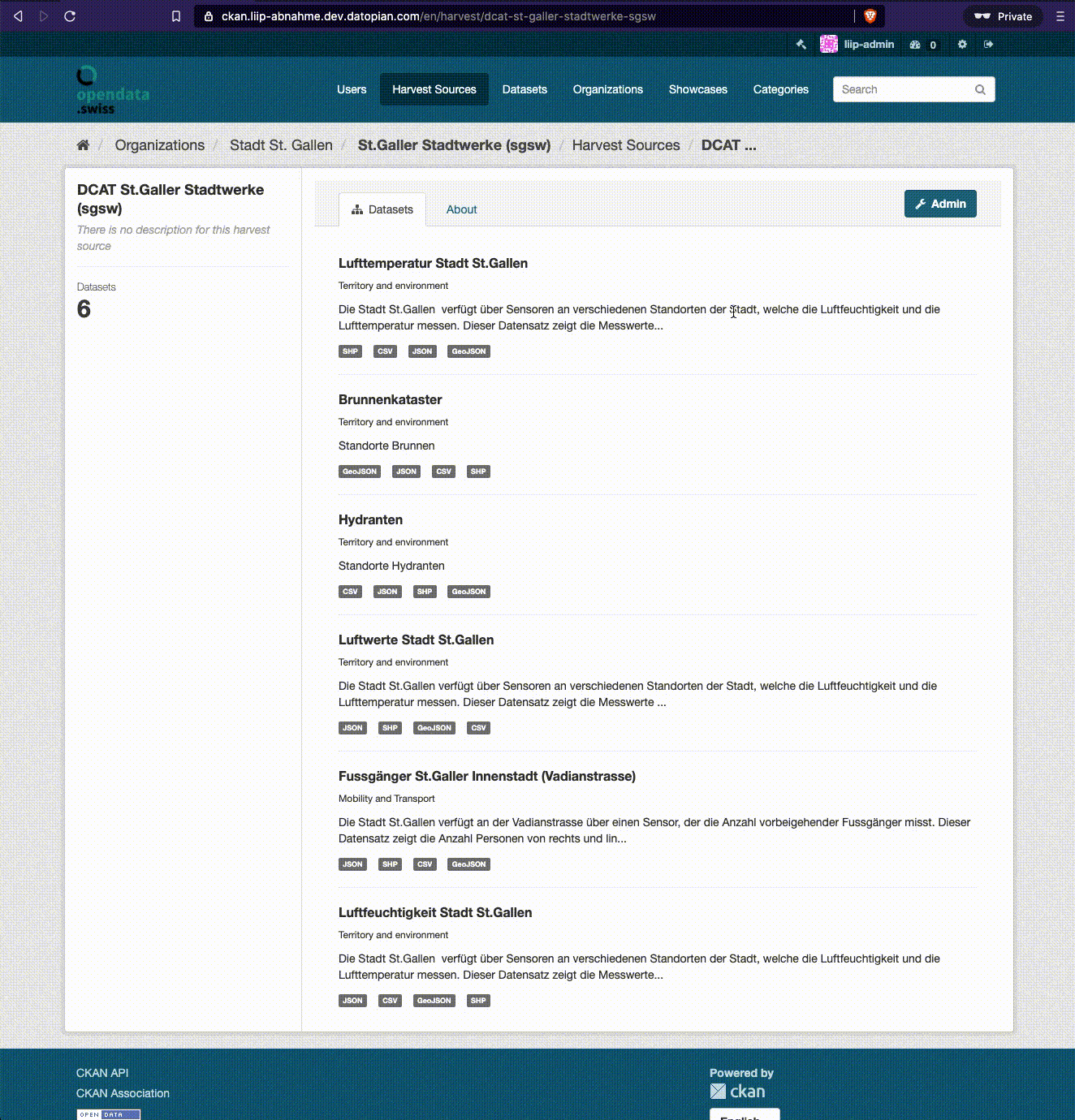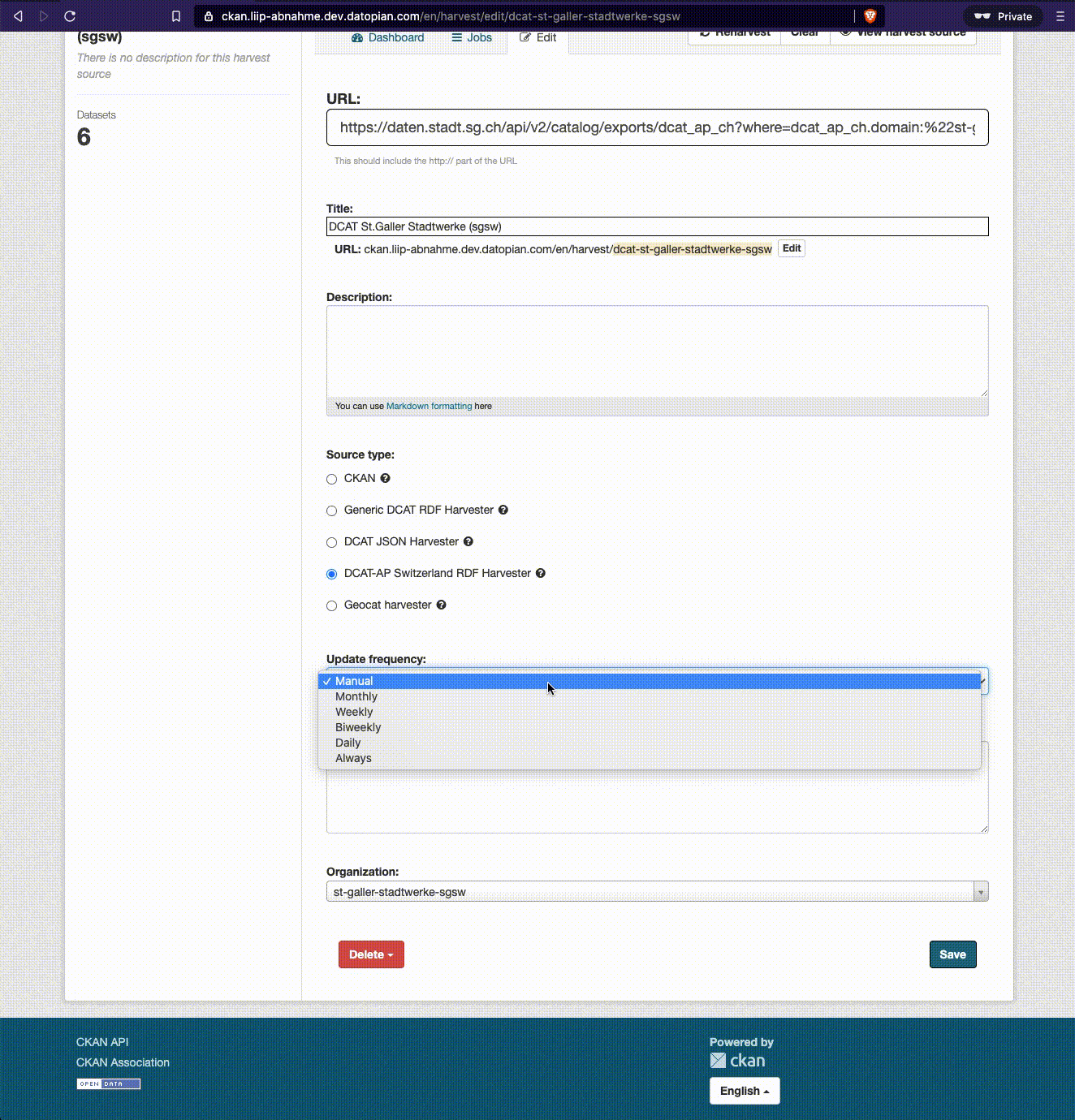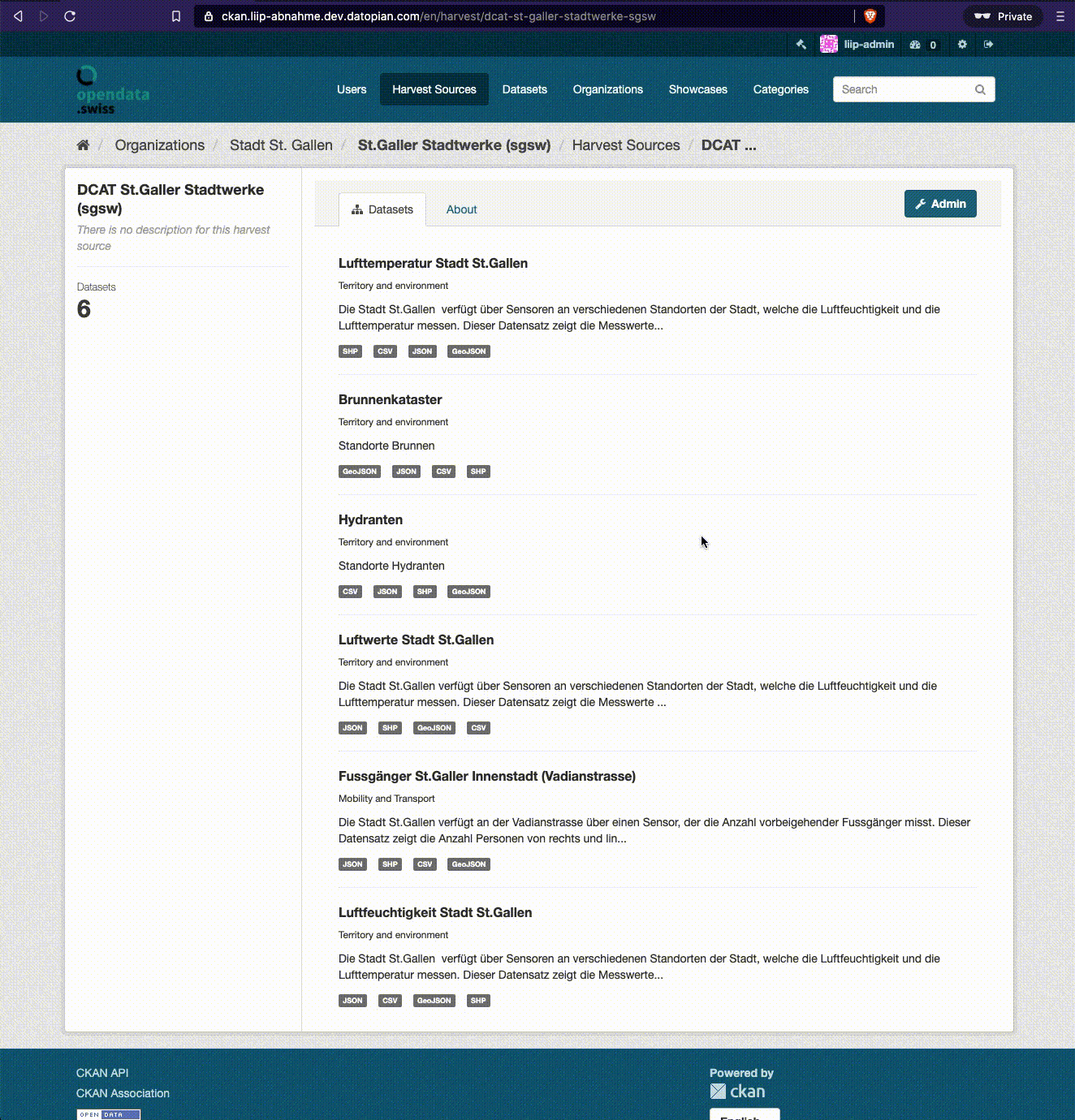
Klicken Sie auf den Button «Administrator» um Ihren Harvester zu verwalten. Sie gelangen dann zu einem Dashboard für das Management Ihres Harvesters.
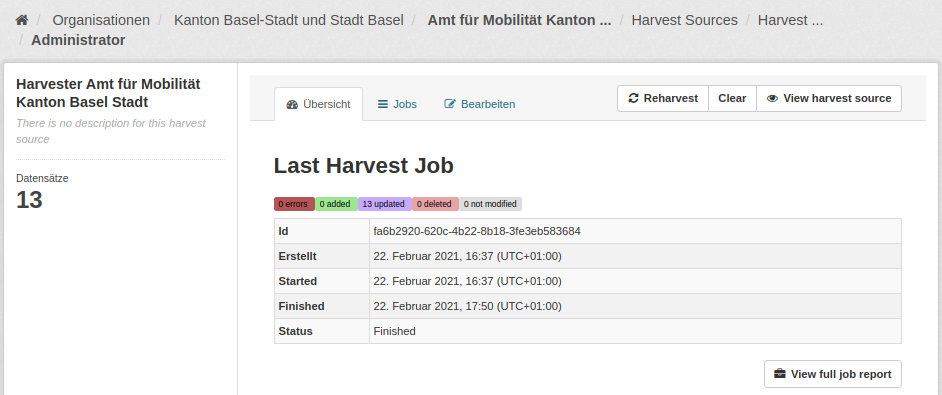
Hier wird Ihnen jeweils der aktuellste Harvest Job angezeigt.
Sie haben folgende Möglichkeiten:
Der Tab «Jobs» führt Sie zu einer Liste vergangener Harvest Jobs
Der Tab «Bearbeiten» führt Sie zur Bearbeitung der Einstellungen Ihres Harvesters
Der Button «Reharvest» stösst einen erneuten Harvesterlauf an, so dass die Datasets anhand dem eingetragenen Katalog-Endpunkt aktualisiert werden
Über den Button «View harvest source» gelangen Sie zurück auf die Detailseite Ihres Harvesters
Vorsicht: Der Button «Clear» löscht alle Datasets und vergangenen Jobs des Harvester. Machen Sie das nur, wenn das wirklich Ihre Absicht ist.
Gut zu wissen
Harvester laufen als Hintergrundprozesse. Wenn Sie Ihren Harvester anstossen, wird dadurch ein Harvest Job erzeugt und in eine Jobqueue gestellt. Wie schnell Ihr Harvest Job Ergebnisse liefert, hängt auch davon ab, wie lang die Jobqueue gerade ist. Deshalb kann die Zeit, die Sie auf die Ergebnisse Ihres Harvesters warten müssen, stark variieren.
Harvesting Fehler beheben
Wenn Ihr letzter Harvest Job Fehler gemeldet hat, sehen Sie das auf dem Dashboard. Klicken Sie dann auf den Tab «Jobs», um zur Jobliste zu gelangen:
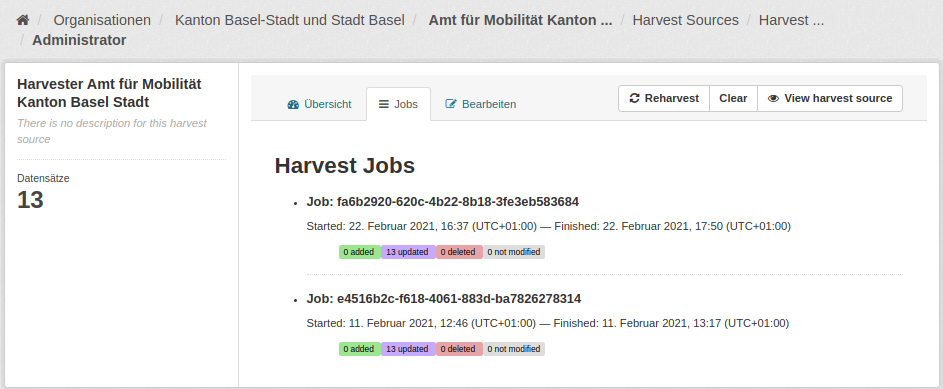
Hier können Sie die Harvesting Fehler im Detail ansehen:
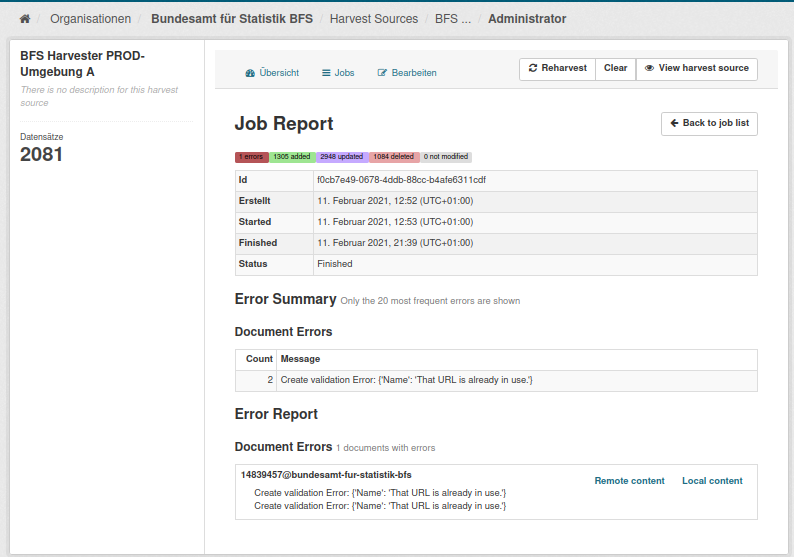
In der «Error Summary» sind die Fehlerarten mit der Häufigkeit ihres Vorkommens gelistet
Im «Error Report» sind alle Fehler einzeln gelistet.
Je nach Art des Fehlers steht Ihnen noch Einsicht in den «Remote Content» und den «Local Content» zur Verfügung:
Im «Remote Content» sehen Sie den Datenkatalog an Ihrem Katalog-Endpunkt so wie der Harvester ihn abholt.
Der «Local Content» betrifft oft nur ein Dataset: hier können Sie in einer JSON Darstellung sehen, wie das Dataset auf opendata.swiss angekommen ist.
Wenn Sie beim Testen Ihres Harvesters auf Fehler stossen, die Sie nicht verstehen und nicht beheben können, dann melden Sie sich bei uns. Wir unterstützen Sie beim Einrichten und Testen Ihres Harvesters.
Harvester Einstellungen
Harvester haben ausser dem Katalog-Endpunkt noch weitere Einstellungen.
Wichtig: Wir haben Ihren Harvester bereits für Sie konfiguriert. Im Normalfall sollten die Einstellungen so bleiben, wie wir es für Sie eingerichtet haben.
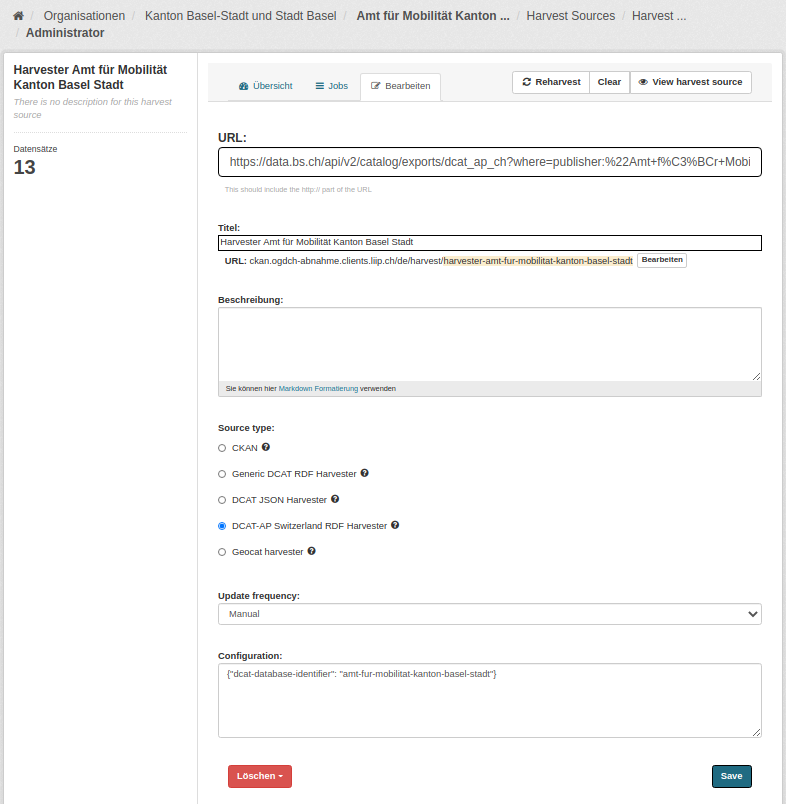
Die «URL» ist der Katalog-Endpunkt an dem Ihre Daten abgeholt werden.
Unter dem «Titel» finden Sie den Harvester in der Harvester-Liste. Das Feld «Beschreibung» ist für Anmerkungen gedacht.
Der «Source type» Ihres Harvesters hängt von der Publikationsvariante ab: in der hier beschriebenen Publikationsvariante hat der Harvester die Einstellung «DCAT-AP Switzerland RDF Harvester». Auch in der Publikationsvariante Metadaten via geocat.ch publizieren kommen Harvester zum Einsatz. Diese haben dann den Typ «Geocat Harvester».
Die Harvester sind bezüglich dem Feld «Update frequency» auf «Manual» eingestellt, obwohl sie täglich laufen, da ihre Startzeit nicht über die Weboberfläche, sondern über Hintergrundprozesse, gesteuert wird. Beim Feld «Configuration» werden gegebenenfalls weitere Konfigurationen eingetragen, die Ihr Harvester benötigt, um Ihre Daten korrekt zu importieren.
Wichtig: Pro Organisation kann es nur einen Harvester mit derselben Konfiguration geben.
Wichtig: Bitte löschen Sie Ihren Harvester nicht, sondern wenden Sie sich an uns, falls Sie ihn nicht mehr benötigen, damit der Harvester und seine Daten fachgerecht entfernt werden können.
Datasets prüfen
Sobald Ihr Harvester fehlerfrei durchläuft, kontrollieren Sie bitte Ihre Datensätze in der Detailansicht des Harvesters:
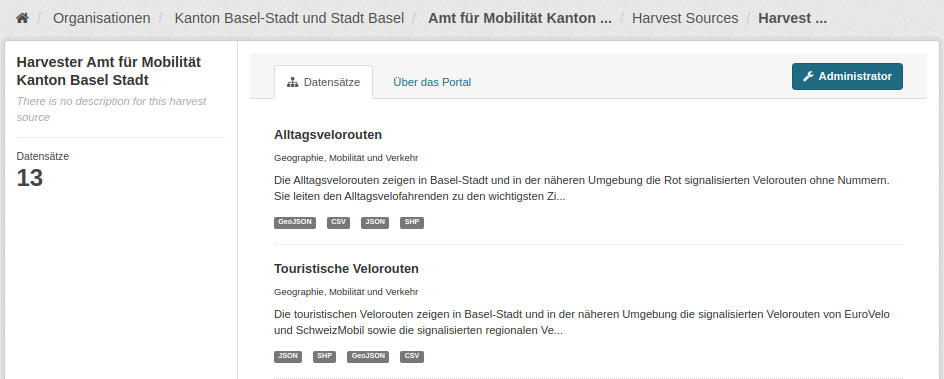
Kontrollieren Sie bitte auch die Frontendansicht Ihrer Datasets:
Sie gelangen zur Ansicht Ihrer Organisation im Frontend,
indem Sie ckan aus der URL Ihrer Organisation im Backend entfernen:


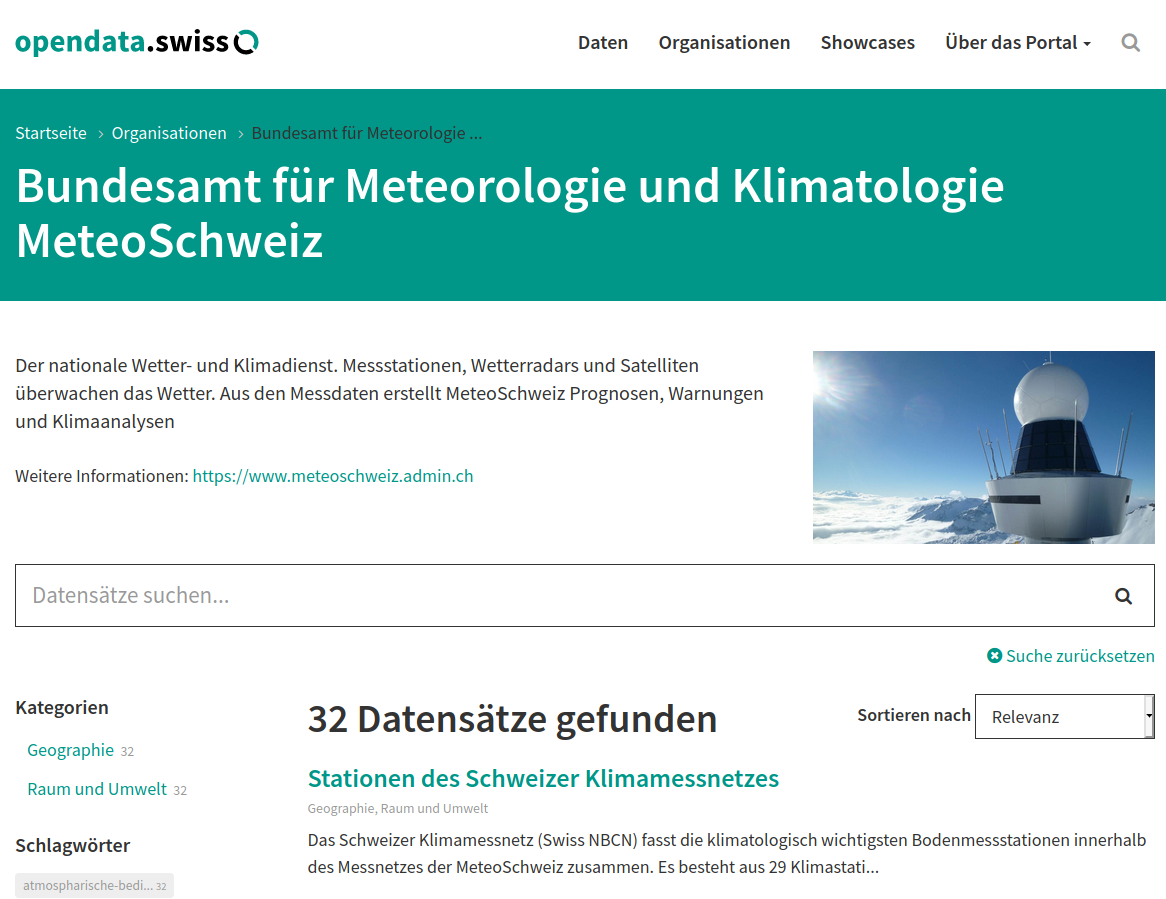
Beispielansicht einer publizierten Organisation
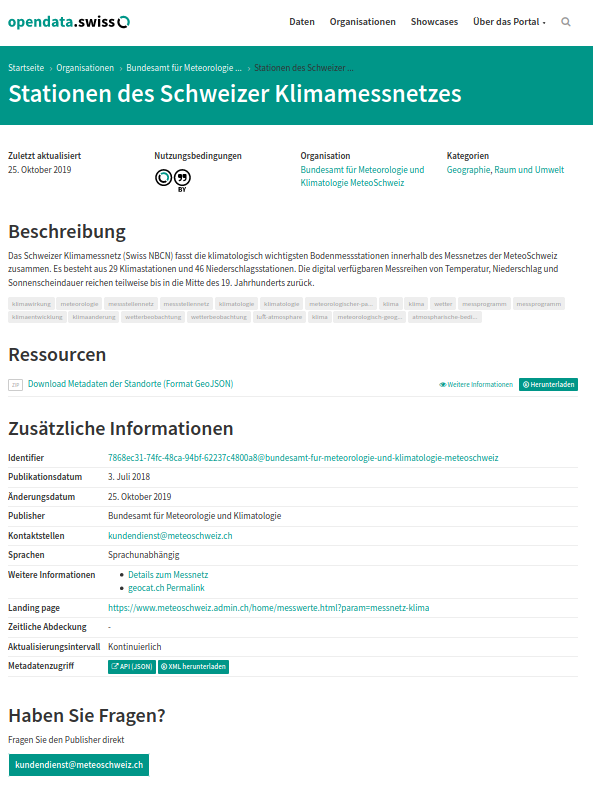
Beispielansicht eines publizierten Datasets
Datasets veröffentlichen
Nach einer abschliessenden Prüfung Ihrer Datasets richten wir das Harvesting für Sie in der Produktionsumgebung ein. Kontaktieren Sie uns, um das Go-Live gemeinsam zu planen.
Support
Sie haben eine Frage zum Harvester? Schreiben Sie uns und wir helfen Ihnen gerne weiter.
DCAT-AP-CH (Link, englisch) – Beschreibung des aktuell von opendata.swiss genutzten Datenstandards DCAT-AP-CH
Harvester konfigurieren- In diesem Screencast zeigen wir Ihnen, wie Sie Ihren Harvester konfigurieren könnenHarvester starten- In diesem Screencast zeigen wir Ihnen, wie Sie Ihren Harvester starten können
{kind=link}
{kind=link}