opendata.swiss unterstützt Linked Open Data. Ziel der von Tim Berners-Lee entwickelten
Bewertungsgrundlage für Daten ist es, dass Datasets vernetzt, selbsterklärend und von
Mensch und Maschine korrekt interpretierbar sind. Hier möchten wir Ihnen das Konzept
näher vorstellen. Der Text ist derzeit nur in Englisch verfügbar.
Today we are surrounded by vast quantities of data playing an
increasingly central role in our lives, and driving the emergence of a
data economy 1. At greater quantities, we are
faced with limitations in traditional methods of organizing data. To
publish machine-friendly data - i.e. in structured form, not as text
documents in natural language - the usual approach is to generate raw
data in standardized files (e.g. spreadsheets as CSV and other
dataformats), or to provide access to
this data through programming interfaces (APIs).
While these go a long way to help make data available and accessible for
knowledge sharing, there is space for improvement in facilitating data
reuse, such as:
Comprehensibility: provide better descriptions of data and
underlying models or schema
Accessibility and share-ability: simplify access, therefore also
facilitate distribution of up-to-date data
Integration: facilitate the combination of data from different
sources into a common point of access
This document describes an approach known as Linked Data, which
responds to these needs.
The World Wide Web has radically altered the way we share knowledge, by
lowering barriers to publishing and accessing linked documents inside of
a global information space 2 . Linked Data
provides a publishing paradigm in which not only documents, but data
itself is a “first class citizen” of the Web (Scott, 2006), extending
the Web with a global data space based on open standards - also known as
the Web of Data.
In summary, Linked Data is about publishing data on top of the Web, and
promoting links between data from different sources, through production
of human- and machine-readable documents. Linked Data is a term used to
describe a set of recommended best practices for exposing, sharing, and
connecting pieces of data, information, and knowledge on the Web’s
HyperText Transfer Protocol (HTTP), using Universal Resource Identifier
(URIs) to identify things and describe them using a data model called
the Resource Description Framework (RDF).
Tim Berners-Lee, inventor of the Web, laid down four
design principles of Linked Data,
providing a recipe for publishing and connecting data using Web
infrastructure, while adhering to its fundamental architecture and
standards:
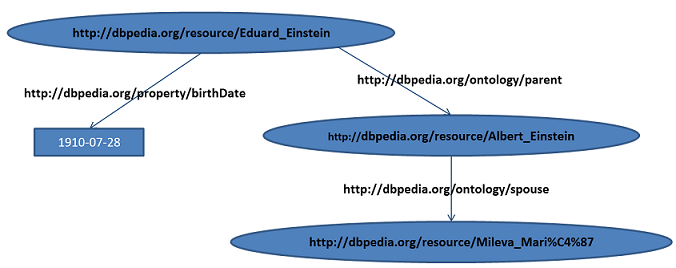
Use URIs to name (identify) things. For instance
http://dbpedia.org/resource/Switzerland was chosen to identify
the country Switzerland in a data source called DBPedia. The well
established Domain Names System (DNS) ensures that this key is unique
worldwide.
Use HTTP URIs so that things can be looked up (interpreted, “dereferenced”).
Retrieving a representation of a resource
identified by a URI is known as dereferencing that URI. By choosing
an URL as the key for the resource (a URL is an HTTP URI), we can
follow the link to get information about that resource. For a user,
it means that by clicking on a URL -
e.g. http://dbpedia.org/resource/Switzerland - she will
directly access the information rendered by a Web browser. Using the
same underlying technology, a computer program could access
structured information, so that the Web works as one database.
Provide useful information about what a name identifies when it is looked up usingopen standards
When you open that page in a browser (by dereferencing the URI), all
the data presented to you comes from the underlying RDF data that is
rendered here as standard HTML. If you want to have a closer look at
that RDF data, you can access it through
http://dbpedia.org/data/Switzerland.
Refer to other things using their HTTP URI-based names when publishing data on the Web.
On Switzerland page of the DBPedia
web site, you will find some related data from other data sources.
For instance, look for the
geodata:Suisse string, and
click on it. You will be directed to the page of the same entity,
Switzerland, on another well known Linked Data source: GeoNames.
Thanks to the use of universal identifiers, these two different data
sources were able to link their data. An end-user can now find a
broad range of information about Switzerland in either of those
sources.
Be aware that those Web resources identified by dereferenceable URIs are
not meant to be directly viewed by end-users, but really serve as a
distributed data base from which software developers may create richer
applications and functions, with user-friendly interfaces.
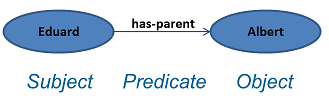
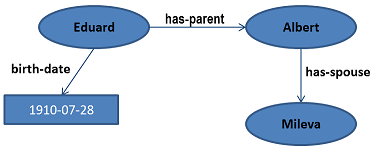
RDF is a data model where each piece of information is a simple sentence
made of three parts: a subject, a relation (or predicate), and an
object, hence the name of triple. The relation is what allows the
creation of connections amongst data (subjects and objects), in other
words to link the data.
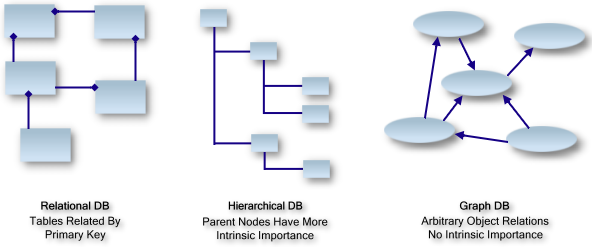
With RDF a new kind of data base was created to store RDF triples,
commonly called a triple store. To query the triples stored in a
triple store, a query language was developed: SPARQL. All of those new
technologies are defined by W3C standards and will be described in more
details further on.
Linked Data is shareable, extensible, and easily re-usable. It supports
multilingual functionality for data and user services, such as the
labeling of concepts identified by URIs. By using globally unique
identifiers to designate works, places, people, events, subjects, and
other objects or concepts of interest, resources can be referenced
across a broad range of sources and thus make integration of different
information much more feasible.
Linked Data aims to break information out of silos where they are locked
to specific data collections and formats, and makes data integration and
data mining over complex data easier. Such technologies allow for easier
updates and extensions to data models - as well as potential to infer
new knowledge out of collections of facts.
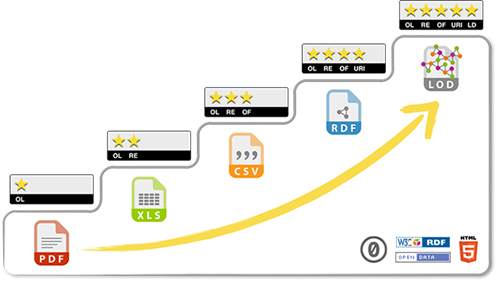
Tim Berners-Lee proposed a rating system for Open Data as shown in
Figure 1. To get the maximum five stars, data must (1) be available on
the Web under an open license, (2) be in the form of structured data,
(3) be in a non-proprietary file format, (4) use URIs as its
identifiers, (5) include links to other data sources. In the specific
context of open data, Linked Open Data is given a 5 stars rating.
make your content available on the Web (whatever format) under an open license
Consumer
✔ You can look at it.
✔ You can print it.
✔ You can store it locally (on your hard disk or on an USB stick).
✔ You can enter the data into any other system.
✔ You can change the data as you wish.
✔ You can share the data with anyone you like
Publisher
✔ It’s simple to publish.
✔ You do not have to explain repeatedly to others that they can use your data.
e.g. XLS
Description
make it available as structured data
(e.g., Excel instead of image scan of a table)
Consumer
All you can do with Web data and additionally:
✔ You can directly process it with proprietary software
to aggregate it, perform calculations, visualise it, etc.
✔ You can export it into another (structured) format.
Publisher
✔ It’s still simple to publish.
e.g. CSV
Description
make it available in a non-proprietary open
format (e.g., CSV as well as of Excel)
Consumer
All you can do with Web data and additionally:
✔ You can manipulate the data in any way you like,
without the need to own any proprietary software package.
Publisher
✔ You might need converters
or plug-ins to export the data
from the proprietary format.
It’s still rather simple to publish.
e.g. RDF
Description
use URIs to denote things, so that people
can point at your stuff
Consumer
All you can do with Web data and additionally:
✔ You can link to it from any other place (on the Web or locally).
✔ You can bookmark it.
✔ You can reuse parts of the data.
You may be able to reuse existing tools and libraries,
even if they only understand parts of the pattern the publisher used.
warning Understanding the structure of an RDF „Graph“ of data can
require more effort than tabular (Excel/CSV) or tree (XML/JSON) data.
You can combine the data safely with other data. URIs are a
global scheme so if two things have the same URI then it’s
intentional, and if so that’s well on it’s way to being 5-star data!
Publisher
✔ You have fine-granular control over the data items
and can optimise their access (load balancing, caching, etc.)
✔ Other data publishers can now link into your
data, promoting it to 5 star!
You typically invest some time slicing and dicing your data.
You’ll need to assign URIs to data items and think
about how to represent the data.
You need to either find existing patterns to reuse or create your own.
e.g. LOD
Description
link your data to other data to provide context
Consumer
All you can do with Web data and additionally:
✔ You can discover more (related) data while consuming the data.
✔ You can directly learn about the data schema.
You now have to deal with broken data links, just like 404 errors in web pages.
Presenting data from an arbitrary link as fact is as
risky as letting people include content from any website in your pages.
Caution, trust and common sense are all still necessary.
Publisher
✔ You make your data discoverable.
✔ You increase the value of your data.
✔ Your own organisation will gain the same benefits from the links as the consumers.
You’ll need to invest resources to link your data to other data on the Web.
1. Richer data, better data integration and reuse
Libraries assets will benefit from descriptions of a higher level of
granularity, without requiring more investment. Linked Data enables
different kinds of data about the same asset to be produced in a
decentralized way by different actors. This is an alternative from the
traditional approach where libraries have to produce stand-alone
descriptions (as MARC records for instance). As a result data quality
will be improved and this will help in the reduction of redundancy of
metadata.
This is made possible by the use of Web-based identifiers which will
also help in different areas, as facilitating navigation across library
and non-library information resources, making up-to-date resource
descriptions directly citable by catalogers, or enhance citation
management software for instance.
Information seekers benefit from improved federated search in new search
applications, but also in existing search engines. Searching services
will be richer, and libraries will improve their visibility through
search engine optimization (SEO).
The history of information technology shows that specific data formats
are ephemeral. Linked Data do not rely on a particular data structure
and is thus more durable and robust than other metadata formats bound to
a specific format.
Linked Data being published in the Web, accessing Linked Data is done in
a uniform and trivial way consisting of HTTP requests. Data consumers do
not need to learn different APIs or library-centric protocols.
This section describes how the Linked Data approach could be implemented
in the domain of Swiss Open Government Data. The proposed 10 steps are
based on the W3C Best Practices for Publishing Linked Data
document, adapted to the
opendata.swiss context. Only the methodological guidelines of each step
are presented here. For further details, please refer to the original
document.
The first step to successfully create a Linked Open Data publishing
process starts by explaining to stakeholders the conceptual Linked Data
approach and the main technical differences compared to other Open Data
publication solutions (the 5 stars Open Data is a good resource here).
Then a data modeling life cycle can be designed based on the following
steps presented here or adapting existing workflows.
In the public administration context, the first barrier to publish data
as “open data” is to have a legal basis allowing it. We thus propose to
start with an already published dataset for which the legal basis
question is already solved. It could be either:
An Excel document that is already made available on one of the web
pages of your organization
A database whose content is already available through a website,
meaning that its content can be searched by a user but not by a
machine (lack of API)
Data sets published in reports (tables) that could have an added
value to be published as row data on the web.
Open Data not yet published: this would be a rare but very valuable
case, where a newly open dataset is not published in any form yet
Moreover, preference can be given to:
Data based on international or national standards
(eCH standards, for instance)
Popular data or data with a high re-use potential
Data that can be easily combined with other open data, and thus
provide greater value
The particularity of Linked Data modeling is that it consists of a
transformation: from the original data (relational database, CSV files,
etc.) to the RDF model. Defining this target data model is the objective
of this step. This can be only achieved by bringing together
domain-specific competencies hold by the data owner and linked data
competencies that must usually be hired somewhere else.
The domain expert will explain the objects and their relationship (local
relationship but also relationships to other data sources) as well as
the standard vocabularies of the domain. The linked data expert will
then look for existing RDF versions of those vocabularies (aka
ontologies), and eventually define a new RDF vocabulary if needed.
4. Specify appropriate terms of use and legal basis
The appropriate terms of use and legal basis should be explicitly
defined along with the dataset, in accordance with the model defined in
Terms of use for
OpenData.swiss.
URIs are at the core of the Linked Data architecture, as they provide
world wide identifiers that promote a large scale “network effects”.
They identify the vocabularies (ontologies), the datasets themselves,
the objects (resources) they contains as well as their relationships.
URI Design Principles Provide dereferenceable HTTP URIs (URL) that
serve as machine-readable representation of the identified resource.
Define a URI structure that will last as long as possible by not
containing anything that could change.
URI Policy for Persistence Define a persistent URI policy and
implementation plan, which relies on the commitment from the URI
owner.
URI Construction Includes guidance coming from URI strategies applied
successful by different organizations
Internationalized Resource Identifiers (IRI) If necessary, the use of
Unicode characters (non-ASCII characters) is possible as long as it
follows existing standards.
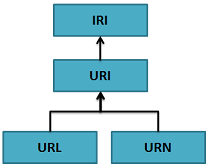
Figure 2. A URL is a specific kind of URI, a URI is a specific kind
of IRI
A URL is a specific kind of URI that is also a location as it is an HTTP
URI and can be looked-up on the Web. In comparison, a URN is a Uniform
Resource Name as an ISBN code for example.
For more details about how to design persistent URIs, please refer to
the original URI Construction
section which
cites references to different documents. We would like to point out that
the Study on persistent URIs
is a nice Web
representation of the very complete
10 Rules for Persistent URIs,
which is the result of a survey done by the SEMIC working group for the
European Commission.
To facilitate the reuse of the data, reuse of standard vocabularies is a
key factor as end-users will need to understand a dataset’s structure to
quickly comprehend and assess it.
Standard vocabularies for Linked Data have been developed, validated and
made available, as for instance:
Existing vocabularies can be found using search tools
(Falcons,
Watson,
Swoogle)
or directories (LOV, the European
Commission’s Joinup platform, or
domain specific portals as the
Bioportal for the biological
domain as an example). To evaluate a vocabulary, take into account if
that vocabulary is published by a trusted group, is well documented and
self-descriptive, is used by other datasets, has persistent URIs and is
accessible for a long period, and if its provides a versioning policy.
If there is a need for a new vocabulary we recommend to contact an
ontology expert to fulfill this task properly.
Once all the former preparation steps have been carried out, it is
possible to perform the data conversion from the original format to
Linked Data (RDF triples). There are many ways to do this using existing
tools available for that mapping operation, see the
W3C list for instance. The
Linked Data expert will know which tool to use for the purpose and, if
needed, will create a new one.
This step should include the generation of metadata for that datasets
(see the official documentation about
DCAT-AP for Switzerland), and also the links to other datasets,
as for instance DBPedia (the Linked Data version of Wikipedia), to make
the new dataset part of the Linked Data Cloud.
The SPARQL Protocol and RDF Query Language (SPARQL) is the standard
query language for RDF. The current version, SPARQL 1.1, is defined by a
W3C recommendation.
It is common practice for Linked Data to provide a service that accepts
SPARQL queries: a SPARQL endpoint. The endpoint returns data in the
requested format as XML or JSON for instance.
Linked Data publishers implicitly promise to guarantee the published
datasets availability according to the predefined URI strategy, as if
signing a “social contract” with the end-users.
This should be done in order to prevent third party applications to
break when encountering an HTTP 404 “Not Found” error while accessing
the data.
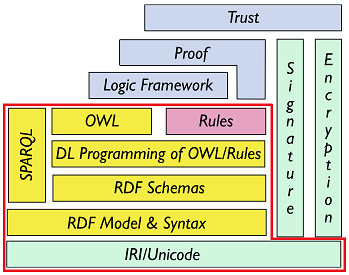
The technical structure underlying the principles of Linked Data are
often illustrated in the form of this “layercake”:
Figure 3. The layer cake for RDF technologies (Source:
w3.org)
This model has evolved through time, as the standards and tools were
further developed and tested. Here follows an introduction to the main
technical bricks (highlighted in red here above):
unambiguous names for resources (for everything): IRIs (URIs, URLs)
a common data model to describe the resources: RDF
schema for the data based on RDF (common vocabularies, ontologies):
RDFS, OWL, SKOS
Linked Data is based on the Resource Description Framework (RDF,
a W3C standard), a framework to
represent information in the Web, expressing information about any
resource (people, things, anything).
RDF is a data model for “things” (resources) and their “relations”,
where each piece of information is an RDF Statement (or RDF Triple) of
the following structure:
<subject><predicate><object>
Such a statement composed of three elements describes how a resource
(the subject) is linked by a property (the predicate) to another
resource or a value (the object)
So where do IRIs, the foundation of the layercake, come into play ?
Everywhere! Everything is identified by a URL (a specific form of IRI),
except literal values, as “1910-07-28” in our running example. We did
not mention any URL in the former presentations to make things simple
and more readable.
There exist different specifications to write a RDF Graph (i.e. RDF
Triples) to a file. This process is called “serialization” and the RDF
1.1 Primer gives the following list:
RDF/XML
(the original 2004 syntax, updated for RDF 1.1)
The most common ones in 2016 are:
Turtle to write down RDF Triples in a text file that will have a
“.ttl” extension (a format that is easily readable by a human and
thus prefered to the RDF/XML version)
JSON-LD to store RDF data in java objects, which is a popular and
practical format for computer programmers
RDFa to add RDF inside HTML pages, the RDF data being not visible to
end-users but at disposal for crawlers.
Turtle is a pretty simple format where each triple is written down.
Our running example can be serialized in Turtle as follow:
RDF was designed to represent data in a machine-friendly way, but we are
still missing an important part of Information Modeling: a Data Model or
Schema. In term of Linked Data and RDF, the data model is called a
“vocabulary” or “ontology”. For that purpose, RDF has been extended by
RDFSchema (RDFs) and the
Ontology Web Language (OWL).
This is also where semantics is added to RDF.
RDFs allows to define Classes and Properties. Classes are used to group
similar resources together by giving one or more types to a resource. In
our example above, Albert, Eduard and Mileva are instances of a class
Person. RDFs can be used to add some semantics to the property “spouse”
for instance, by saying that the object and subject of this property are
instances of the class Person. This information could serve for further
checking or reasoning.
OWL goes one step further to define logical axioms and rules that can be
further used by an inference engine to deduce new facts out of implicit
knowledge. As a simple example, the “spouse” property can be defined as
“symmetric”, in which case an inference engine would deduce from the
triple <Albert><has-spouse><Milena> a new triple
<Milena><has-spouse><Albert>. Without that inference, querying for
the spouse of Milena would give no result.
The RDF data model is thus a common language for the schema and the data
as well.
As described in the W3C’s “Best Practices for Publishing Linked Data”,
there are different ways to provide machine access to data, and thus
different ways for a end-user to access the data.
We will conclude with our example by showing how an end-user can access
or query that data which comes from the DBPedia site.
Direct URI resolution:
Any of the mentioned resources can be dereferenced by simply accessing
the following URLs:
DBPedia datasets are available for download from
wiki.dbpedia.org
SPARQL endpoint:
The databases for RDF are called Triple Stores, a specific kind of Graph
Databases. RDF data in a triple store can be exposed for direct querying
through a SPARQL endpoint. The SPARQL endpoint for DBPedia can be
accessed here
To give it a try, please copy/paste the following SPARQL query to ask
for the spouse(s) of Albert Einstein (note that the SPARQL syntax is
similar to the Turtle format), and hit the “run query” button to see the
results:
Tom Heath and Christian Bizer (2011) Linked Data: Evolving the Web
into a Global Data Space (1st edition). Synthesis Lectures on the
Semantic Web: Theory and Technology, 1:1, 1-136. Morgan & Claypool.
10. Social Contract of a Linked Data Publisher
Linked Data publishers implicitly promise to guarantee the published datasets availability according to the predefined URI strategy, as if signing a “social contract” with the end-users.
This should be done in order to prevent third party applications to break when encountering an HTTP 404 “Not Found” error while accessing the data.